Как выбрать нейросеть под свои задачи?
(обновлено 5 марта 2025)Большой туториал от создателя VseGPT. Можете прочитать последовательно или сразу перескочить к интересующему вас разделу.
Все модели находятся на странице Модели в меню сайта – далее будут приводится только названия.

Общая информация
Коротко для тех, кто не знает: текстовые нейросети делятся на проприетарные и опенсорсные.
Проприетарные предоставляются соответствующими компаниями по API (т.е. веса для них недоступны, запустить их у себя нельзя). Самые известные из них это:
- OpenAI: ChatGPT, GPT-4, GPT-4-Turbo
- Claude: 3 Haiku, Sonnet, Opus
- Google: Palm, Gemini Pro
- ну и некоторые другие, например Mistral, Perplexity.
Компании эти запускают эти модели на своих серверах (это быстро, это плюс), но под своими условиями доступа к API (это минус, условия бывают очень разные).
Также есть опенсорсные текстовые нейросети — веса для них выложены, любой желающий может их дотюнить (дотренировать) под свои задачи, и запускать совершенно независимо от оригинального автора (детали лицензий мы сейчас опускаем)
Это конечно, несомненный плюс, но несомненным минусом является то, что предоставлять инстанс (т.е. сервер, обрабатывающий модель) никто не будет, и нужно запускать её самостоятельно — что часто очень дорого (т.к. надо арендовать машину с GPU) или медленно (если вы используете оптимизации и гоняете модель на CPU).
В опенсорсе также есть понятие базовых моделей и дотюненных моделей.
Базовая модель тренируется с нуля какой-то большой компанией (потому что затраты на тренировку с нуля велики), а затем выкладывается в опенсорс. Дальше, уже небольшими усилиями энтузиасты дотренировывают базовую модель на своих данных под конкретные задачи.
Наиболее известные и часто используемые базовые модели сейчас это:
- Llama2 7B, 13B, 70B от компании Meta* (признана экстремистской и запрещена в России)
- Mistral 7B, Mixtral 8x7B, Mixtral 8x22B от французского стартапа Mistral
- Yi-34B (от китайской компании 01.ai с фокусом на английском и китайских языках)
Цифры в конце означают число параметров в модели — чем больше, тем модель в целом умнее в плане следования логике, но тем дороже обходится её дотренировка и запуск. Дотюненные модели обычно сохраняют имена или размеры базовых моделей в своем названии, так что обычно всегда можно понять, на какой базе дотренировывалась модель.
Давайте теперь быстро по общим принципам подбора.
Общие принципы подбора моделей под свои задачи
Выбирайте свежее, в пределах последних 3–6 месяцев
Как правило, чем позже была выпущена модель, тем на большем числе данных и с большими известными оптимизациями она тренировалась (например, более поздняя Mistral 7B находится на уровне более крупной Lllama 13B). Также обычно более поздние модели предоставляются дешевле, т.к. для них уже придуманы какие-то оптимизации.
Больше — лучше, но дороже и медленнее
Как правило, у компаний есть более слабые и более сильные модели (тот же ChatGPT против GPT-4) — и это связано с числом параметром в них.
Если вам нужно максимальное качество, нужно выбирать самую дорогую модель (или модель с большим числом параметров в опенсорсе, и там она обычно тоже будет дорогой — т.к. чем больше модель, тем дороже аренда сервера для её запуска)
Если вы решаете массово какие-то простые задачи в духе “определи тональность этого текста”, имеет смысл выбрать более дешевые и простые модели.
Коротко – заходите на страницу моделей по новизне и ищите, начиная сверху или по ключевым словам.
Или на основную страницу моделей – выбираете интересующего вас провайдера и берете самые последние модели (сверху)
Или на основную страницу моделей – выбираете интересующего вас провайдера и берете самые последние модели (сверху)
Конкретные задачи
В качестве примеров я обычно буду приводить модели, доступные на VseGPT — просто потому, что я с ними сам работал.
Для начала, если не знаете, что выбрать...
Я бы предложил поработать с:
- Старым добрым ChatGPT – последняя модель это OpenAI: GPT-4o Или возьмите gpt-4o-mini – если нужно дешево
- Claude 3.7 Sonnet. Sonnet 3.7 вообще по метрикам лучше большинства сетей, в том числе топовых. Очень много где в этом туториале я буду рекомендовать его.
Если нужно максимально дешево…
…используйте:
- Google Gemini Flash
- OpenAI: gpt-4o-mini
- Claude 3 Haiku
- DeepSeek Chat
Если нужно решать задачи программирования…
…я использую Claude Sonnet 3.7.
Больше года назад я использовал для программирования простой ChatGPT и очень об этом жалею — мне приходилось править мелкие недостатки в коде руками, но тогда я считал это нормальным. Claude Sonnet 3.7 при хорошей постановке задачи сразу пишет весьма хороший объемный код.
Если же нужно максимально дешево – имеет смысл посмотреть в сторону других дешевых моделей.
Если нужно обработать большие файлы…
…то надо смотреть, какой размер контекста у модели (есть на странице моделей). Чем больше контекст, тем больше данных влезет в модель для обработки.
Но тут эволюция идет очень быстро, имеет смысл следить за изменениями.
Где-то в июне 2023, базовая ChatGPT имела контекст в 4096 токенов, 16к-версия была прилично дороже, а базовая GPT-4 имела контекст в 8000 токенов. Опенсорсные модели же запускались на 2К контекста, и пользователи жаловались, что диалог туда почти не влезает.
Сейчас же базой является контекст в 100–200К.
Так что — если вы обрабатываете небольшие и даже большие статьи, то вы обычно можете выбирать модель по своему вкусу.
Если же все-таки нужен максимальный контекст, то рекомендую смотреть в сторону Google Flash. – там контекст доходит до 1 млн токенов.
Если нужен переводчик…
…то можно ознакомиться с
Коротко — чем умнее сеть, тем лучше перевод.
Но особенно могу рекомендовать Claude 3.7 Sonnet. Сложно сказать, что у Claude с логическим мышлением, но именно с художественностью текста они работают на прекрасном уровне.
Если же вам нужен самый дешевый переводчик — рекомендую взять Google Flash 1.5; или даже бесплатный совершенно обычный Google Translate — по моим метрикам он вполне на уровне. Также Flash может быть лучше в переводе художественного текста; Sonnet же очень хорошо справляется с non-fiction.
Используйте Нейропереводчик на нашем сайте – там есть хорошие примеры.
Или посмотрите ряд приложений для перевода, которые хорошо интегрируются с нашим сервисом
Или посмотрите ряд приложений для перевода, которые хорошо интегрируются с нашим сервисом
Если нужен сторителлинг (написание художественного текста) или ролеплей (взаимодействие с выдуманным персонажем)…
…то есть два пути.
Официальные модели от больших компании используют фильтры, чтобы не отвечать на некоторые вопросы по “чувствительным” темам.
Например, сейчас запрос про попа в ChatGPT проходит нормально, а раньше вызывал срабатывание фильтра.
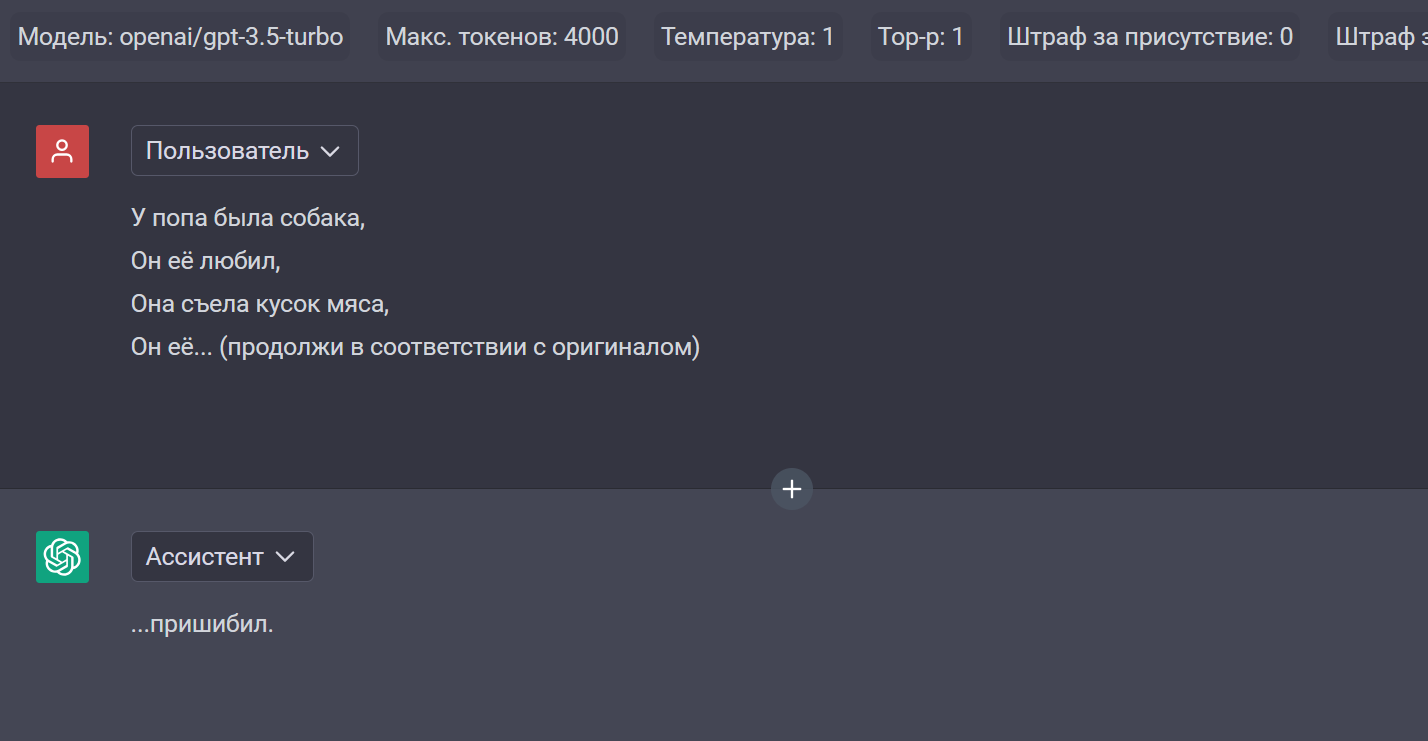
Если вы уверены, что вы не затронете чувствительные темы в своем диалоге — моя рекомендация — Claude 3.7 Sonnet
Я до этого пробовал ролеплеить с ChatGPT и было несколько… механистично. Ролевики посоветовали Claude и, должен сказать, художественный текст у неё получается сильно лучше.
Кроме того, контекст в 200К для больших текстов — это прям конечно очень хорошо. Я в своей практике добирался до 20К в диалоге, и было очень приятно, когда модель помнила что-то из самого начала.
Если же на ваш запрос вы получаете постоянно что-то в духе “Я большая языковая модель, и мне некомфортно говорить на эту тему, давайте о чем-нибудь другом” — имеет смысл обратиться к опенсорсным моделям.
Ранее имело смысл общаться с моделями на английском (ролеплей был лучше), но сейчас, в марте 2025 это уже в целом не актуально.
Что из моделей можно посоветовать? (Буду писать только то, что на сервисе, и что я немного пробовал)
- Google Gemma 9B – немного глуповата, но неплохой русский.
- EVA Qwen2.5 72B v0.2 — базовая китайская Qwen 2.5 72B ОЧЕНЬ НЕПЛОХА в художественном русском тексте. Тут дотюненый для ролеплея вариант.
- Сайга MistralNemo 12B v1 или SAINEMO-reMIX – это модель Mistral Nemo 12B, дотюненая российскими энтузиастами на ролеплей. (Эти модели у нас предоставляются в формате OMF – Open Models Fan – и иногда могут тормозить и быть, увы, недоступны)
- OMF-Qwen2.5–72B-Instruct-abliterated – немного дотюненая модель Qwen2.5–72B с меньшей цензурой. (Эти модели у нас предоставляются в формате OMF – Open Models Fan – и иногда могут тормозить и быть, увы, недоступны)
- EVA Llama 3.33 70b – также файнтюн от команды EVA, но LLama 3.3 от Meta (т.е. не китайской Qwen). Может, лично вам подойдет лучше.
Совет: опенсорс модели более капризные в настройке, чем проприетарные. Я рекомендую при взаимодействии с ними сразу устанавливать температуру меньше 1 — от 0.5 до 0.9. Особенно это важно для моделей на базе китайской Qwen для того, чтобы на выходе не было иероглифов.
Если нужно получать в ответе актуальную информацию, в том числе из Интернета…
…используйте модели Perplexity.
Нет, понятно, что если вы работаете руками, можно воспользоваться онлайновым Google Bard или Bing — они тоже по запросу попытаются найти информацию в интернете. Но если нужно сделать в вашем приложении запрос по API и получить ответ на основе актуальной информации — такую фичу предоставляет только Perplexity.
Совет: из всех предложенных Perplexity моделей используйте sonar-online — она лучше всего отвечает на русском языке.
Примеры:
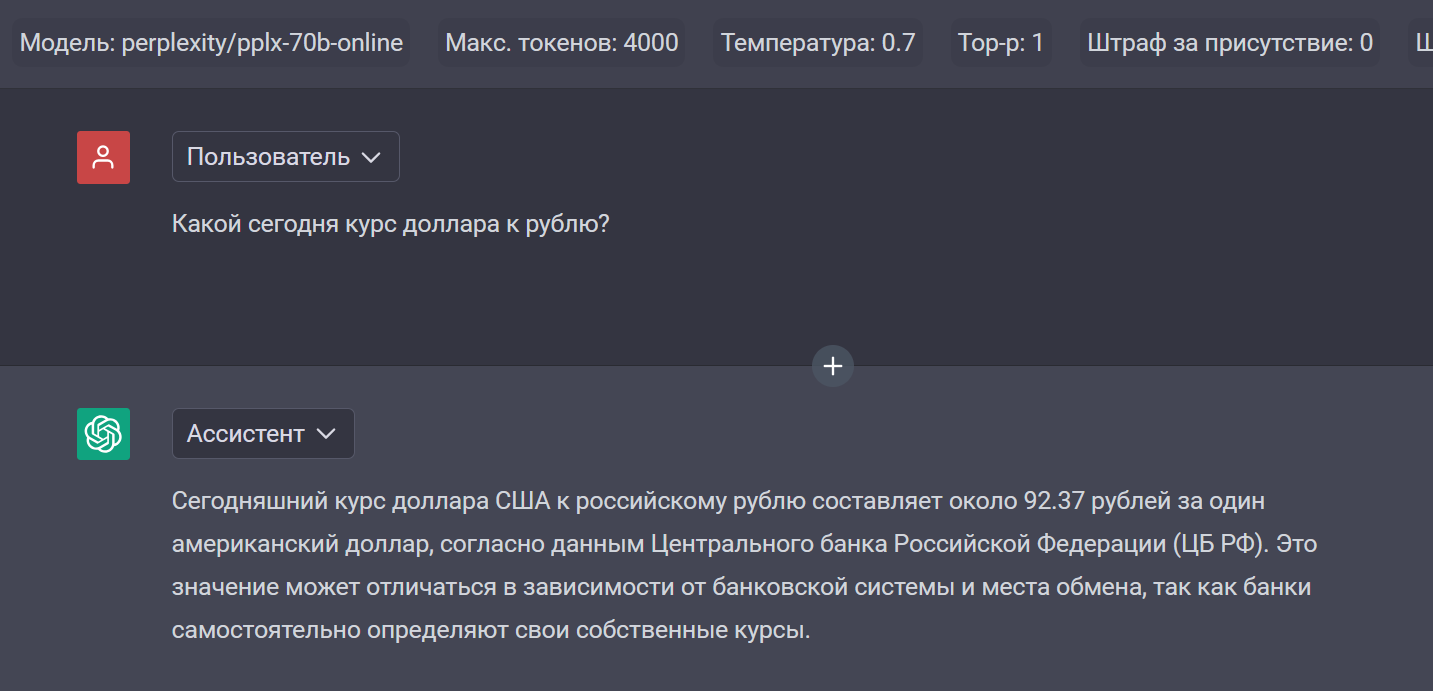
Также можно попросить проанализировать ссылку:

Интересный факт:
На сайте Peprlexity в своем собственном интерфейсе выдает ответы на вопросы со ссылками на источники — так, что можно проверить, откуда сеть взяла свои факты. Пользователи очень просят добавить возможность получать список источников при вызове по API — но пока, несмотря на все просьбы, этой функциональности нет.
Если нужно решать задачи SEO и копирайтинга…
…я бы рекомендовал попробовать модели с неплохим русским языком, отличные от ChatGPT — например, Google Gemini Pro или Claude 3.7 Sonnet.
Попробуйте несколько и посмотрите, что вам лучше подойдет.
Автор: Владислав Январев, 19 апреля 2024, обновлен 5 марта 2025
Материал подготовлен при поддержке хостинг-провайдера Timeweb Cloud